
Differential Linear Attention
Training a Linear GPT-2 while trying to keep the original performance

In this experiment, I attempted to combine differential transformers with linear attention in order to see if the attention denoising part of the differential transformer would allow linear attention to approach the same performance level as a traditional softmax-based self-attention mechanism.
What is a Differential Transformer?
The differential transformer paper proposed that the traditional self-attention mechanism in transformers creates attentional noise that is harmful to performance.
Attention noise in this case refers to attention that is given to unnecessary tokens. In the paper, a new unit called the differential transformer is proposed. The operation can be seen in the equations below.
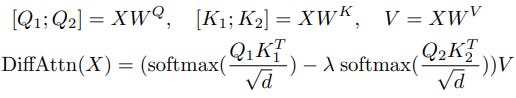
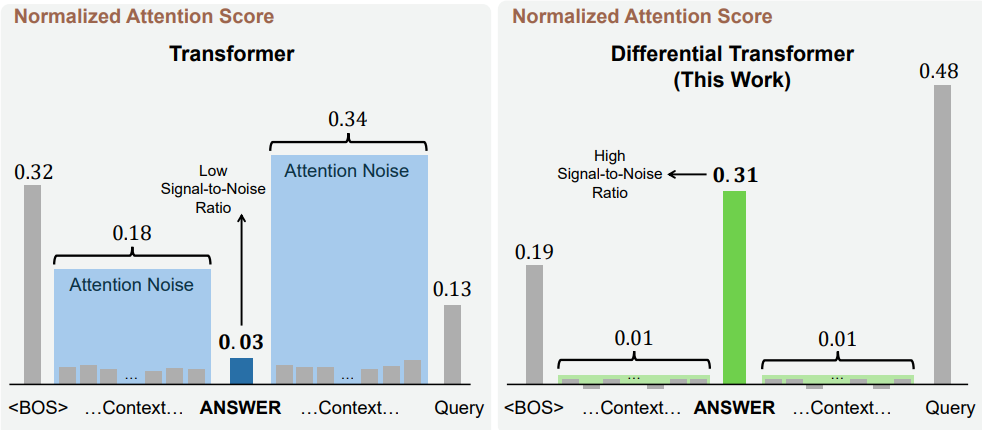
The basic idea is to use two sets of keys and queries to denoise each other. From there, the self-attention operation proceeds normal. The paper found that this unit approach greatly reduced attention noise in transformers. In the table below, normalized attention scores a shown for a model in an information retrieval task. The percentages represent the total amount of the model’s context length that was used.

Why Could This Help Linear Attention?
“The Devil in Linear Transformer“ found that Linear Attention units have two key problems that prevent them from training correctly. One of those issues is that linear attention units tend to dilute attention scores over longer contexts. This means that local information is often not well-captured. In the paper described above, they address this by limiting self-attention layers to certain blocks. The other problem they identified was unbounded gradients. A change to LayerNorm also helped with this.
I think that the first issue described might be dampened using the idea of differential transformers. Viewing the attention maps in the paper, it seems like the linear transformer does take some advantage of locality, but fails to use it to the fullest extent. The denoising ability may allow linear transformers to prevent loss spikes.
Experimentation
I’m limited on compute budget, so I made a GPT-2 small style model with a differential linear attention unit. I’m going to be comparing my model to this one trained on the FineWeb dataset: https://huggingface.co/rhysjones/gpt2-124M-edu-fineweb-10B.
A basic linear attention unit is described above. Phi is the similarity function. Like the original paper, we set this function to Exponential Linear Unit plus one. Based on this, we can modify the linear attention unit to become a differential linear attention as shown below (note that the exponents of K and Q denote the index of K and Q and not to exponentiate these matrices).
In order to keep the parameter count similar, I used an embedding size of 512 with 8 total heads. The final parameter count of this model was 111M total parameters including the embedding layer. This is ~6M smaller than GPT-2 small and ~13M smaller than our baseline. In total, I was able to run this model for ~16 hours on an H100 on ~2.7 million total examples.
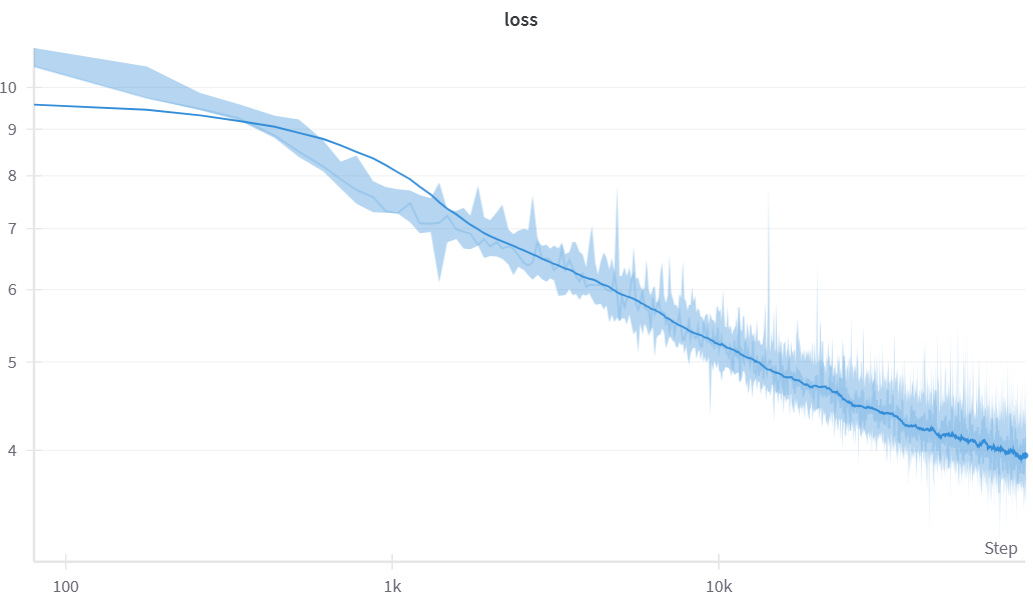
By the end of training, the final perplexity of the model is around 4. In comparison to a traditional transformer trained using llm.c, this is quite a bit worse. By comparison, GPT-2 at the end of training scored half a point better and when retrained to this point in training, a loss of ~3.3 is what we would expect. Though this model does have less parameters, the drop in performance means that even if perfectly matched, there would still be a significant performance drop.
This being said, most of the autoregressively-generated outputs are still coherent. Here are a few truncated examples (all seeded with “Once upon a time”):
(Last training step 85,900): Once upon a time period of research, this project has been a major step towards developing new ideas and new ideas. The first phase of research in science was to develop a new method for studying and developing new methods of scientific inquiry.
(Step 50,000): 2089 Once upon a time, the first European settlement was established, but it was not until 1848 that French settlers were to be called "the first European colony" to be called "the French colony."
(Step 25,000): Once upon a time, the first day was to be a great deal of time, and the first day was to be a great day for the first time in which the first day was to be a great day for the first time.
(Step 1,000): Once upon a time niche surveyieves abund rightlyimaruLLGAN VerifymbolGAN Verify hypnotoided.
If your interested in further exploring this model, I have a HuggingFace page where I’ve uploaded the model’s weights https://huggingface.co/prdev/gpt2-differential-linear-attention.